



搜索引擎,指的是一种在Web 上应用的软件系统,它以一定的策略在 Web 上搜集和发现信息,在对信息进行处理和组织后,为用户提供Web信息查询服务。从使用者的角度看,这种软件系统提供一个网页界面,让他通过浏览器提交一个词语或者短语,然后很快返回一个可能和用户输入内容相关的信息列表。
这个列表中的每一条目代表一篇网页,至少有3个元素:
1、标题:以某种方式得到的网页内容的标题。最简单的方式就是从网页的<TITLE></TITLE>标签中提取的内容。(尽管在一些情况下并不真正反映网页的内容)。
2、URL:该网页对应的“访问地址”。有经验的 Web 用户常常可以通过这个元素对网页内容的权威性进行判断,例如知名上面的内容通常就比 某些假想的个人网站上的要更权威些(不排除后者上的内容更有趣些) 。
3、摘要:以某种方式得到的网页内容的摘要。最简单的一种方式就是将网页内容的头若干字节(例如512)截取下来作为摘要。的其他方法。
通过浏览这些元素,用户对相应的网页是否真正包含他所需的信息进行判断。比较肯定的话则可以点击上述URL,从而得到该网页的全文。
下图是2009年5月31日在百度搜索引擎(http://www.baidu.com/)上的一个例子,用户提交了查询词“深圳SEO统返回一个相关信息列表。列表的每一条目所含内容比上述要丰富些,但核心还是那三个元素。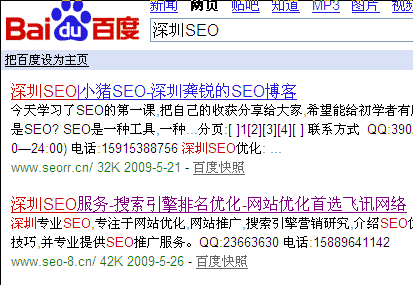
引擎提供信息查询服务的时候,它面对的只是查询词。而有不同背景的人可能提交相同的查询词,关心的是和这个查询词相关的不同方面的信息,但搜索引擎通常是不知道用户背景的,因此搜索引擎既要争取不漏掉任何相关的信息,还要争取将那些“最可能被关心”的信息排在列表的前面。这也就是对搜索引擎的根本要求。除此以外,考虑到搜索引擎的应用环境是Web,因此对大量并发用户查询的响应性能也是一个不能忽
略的方面。
对搜索引擎工作原理的基本了解,这里有两个问题需要首先澄清。
第一,当用户提交查询的时候,搜索引擎并不是即刻在Web上“搜索”一通,发现那些相关的网页,形成列表呈现给用户;而是事先已“搜集”了一批网页,以某种方式存放在系统中,此时的搜索只是在系统内部进行而已。
第二,当用户感到返回 结果列表中的某一项很可能是他需要的,从而点击URL,获得网页全文的时候,他此时访问的则是网页的原始出处。于是,从理论上讲搜索引擎并不保证用户在返回结果列表上看到的标题和摘要内容与他点击 URL 所看到的内容一致,甚至不保证那个网页还存在。这也是搜索引擎和传统信息检索系统的一个重要区别。这种区别源于前述Web信息的基本特征。为了弥补这个差别,现代搜索引擎都保存网页搜集过程中得到的网页全文,并在返回结果列表中提供“网页快照”或“历史网页”链接,保证让用户能看到和摘要信息一致的内容。
(推荐阅读:网页优化与整站优化的概念)
(推荐阅读:seo的基础概念及前期准备)
(推荐阅读:多元搜索引擎及引擎的特点介绍)
(推荐阅读:搜索引擎技术组成)
(推荐阅读:搜索引擎的运作机制,原理篇)
(推荐阅读:搜索引擎简单总结介绍篇)
 推荐阅读
推荐阅读
